
OpenCL FPGA
An indispensable part of our modern life is scientific computing which is used in large-scale high-performance systems as well as in low-power smart cyber-physical systems. Hence, accelerators for scientific computing need to be fast and energy efficient. Therefore, partial differential equations (PDEs), as an integral component of many scientific com puting tasks, require efficient implementation. In this regard, FPGAs are well suited for data-parallel computations as they occur in PDE solvers. However, including FPGAs in the programming flow is not trivial, as hardware descrip tion languages (HDLs) have to be exploited, which requires detailed knowledge of the underlying hardware. This issue is tackled by OpenCL, which allows to write standardized code in a C-like fashion, rendering experience with HDLs unnecessary. Despite the high abstraction level of OpenCL, very energy efficient PDE accelerators on the FPGA fabric can be designed, making the FPGA an ideal solution for power-constrained applications.
Nevertheless, these energy efficient OpenCL designs require profound optimizations, which are implemented in the OpenCL kernels of the PDE solver. Applying these optimization schemes is not a trivial task, thus, a certain level of experience is required. Deploying optimization techniques leads to a huge impact on performance. As shown in the figure below, speedups of up to 1000 times are achieved for some of the kernels of the PDE solver: vectorAdd, cdot and Laplace.
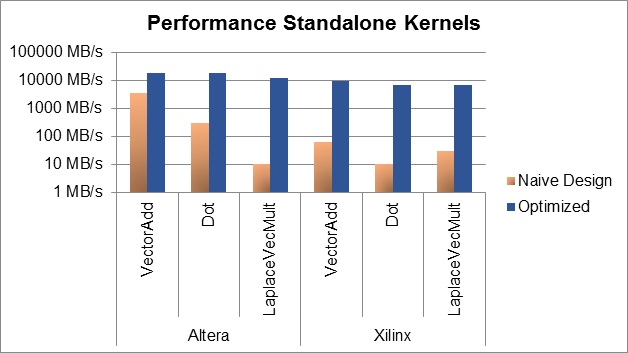
These optimization schemes can be subdivided into vendor-independent and vendor-specific techniques. As their impact differ among different FPGA families, OpenCL kernels are not portable, thus, each OpenCL design deploys a unique set of optimization schemes.
We compared the performance, power consumption and energy efficiency of PDE solvers among different platforms, including multi-core CPUs, GPGPUs and different families of FPGAs. The specification of each platform is depicted below:
| Platform | Specification | API |
Theortical Memory Bandwidth |
Technology | |
|---|---|---|---|---|---|
| CPU | Intel Core i5-4590 | 4 cores @ 3.3 GHz | OpenMP | 21.2 GB/s | 22nm |
| GPU | Intel HD Graphics 4600 | 20 exec. Units @1.15 GHz | OpenCL | 21.2 GB/s | 22nm |
| Nvidia GeForce GTX 980 | 2048 CUDA Cores @ 1.1 GHz | CUDA | 224 GB/s | 28nm | |
| FPGA | Xilinx Virtex 7 | XC7VX690T@200 MHz | OpenCL | 10.6 GB/s | 28nm |
| Altera Stratix V GX | 5SGXEA7 @300 MHz | OpenCL | 21.2 GB/s | 28nm |
The Conjugate Gradient Algorithm (CG) was implemented on each platform and the discretized Laplace differential equation– which led to a system of linear equations, containing the Laplace matrix – was solved. The results are summarized below.
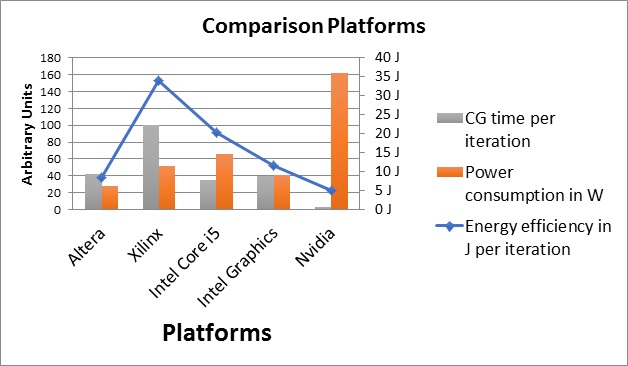
It can be seen clearly that, the Altera FPGA has the lowest energy consumption while comparable performance to the Intel CPU and Intel GPU. With respect to energy efficiency, the Altera FPGA is the best choice for power-constraint systems. The reason for worse performance of the Xilinx FPGA was lower maximum memory bandwidth, as can be seen from the specification.
Source Code:
The kernel codes for the Altera and Xilinx FPGAs as well as the licenses can be found from the following link.
Citation:
D. Weller, F. Oboril, D. Lukarski, J. Becker, and M.B. Tahoori, "Energy Efficient Scientific Computing on FPGAs using OpenCL", in Proceedings of the ACM/ SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA), 2017, USA.